Peak-calling strategies¶
The peak-calling stage finds polyadenylation sites (PAS) within each merged
"peak region" (a stretch of contiguous 3'-end coverage). PeakATail ships four
registered strategies — each implements PeakFinderStrategy in
ema/strategies/, each registered via @register("<name>").
Selection is CLI-level: ema run --peak-strategy <name> or strategy: in the
YAML config.
Strategy overview¶
| Strategy | Class | Best for | Multi-PAS? |
|---|---|---|---|
original |
OriginalStrategy |
A/B baseline; matches the legacy Peak.pasfind() output exactly |
1 PAS per region only |
lambda_poisson |
LambdaPoissonStrategy |
MACS2-style single-peak detection with local background | 1 PAS per region |
sierra_iterative |
SierraIterativeStrategy |
Recovering multiple PAS per 3' UTR (closest to Sierra, Patrick et al. 2020) | Yes — iterative subtraction |
lambda_gradient |
LambdaGradientStrategy |
Multiple-PAS detection with Poisson significance per candidate | Yes — gradient-based candidate detection + per-summit test |
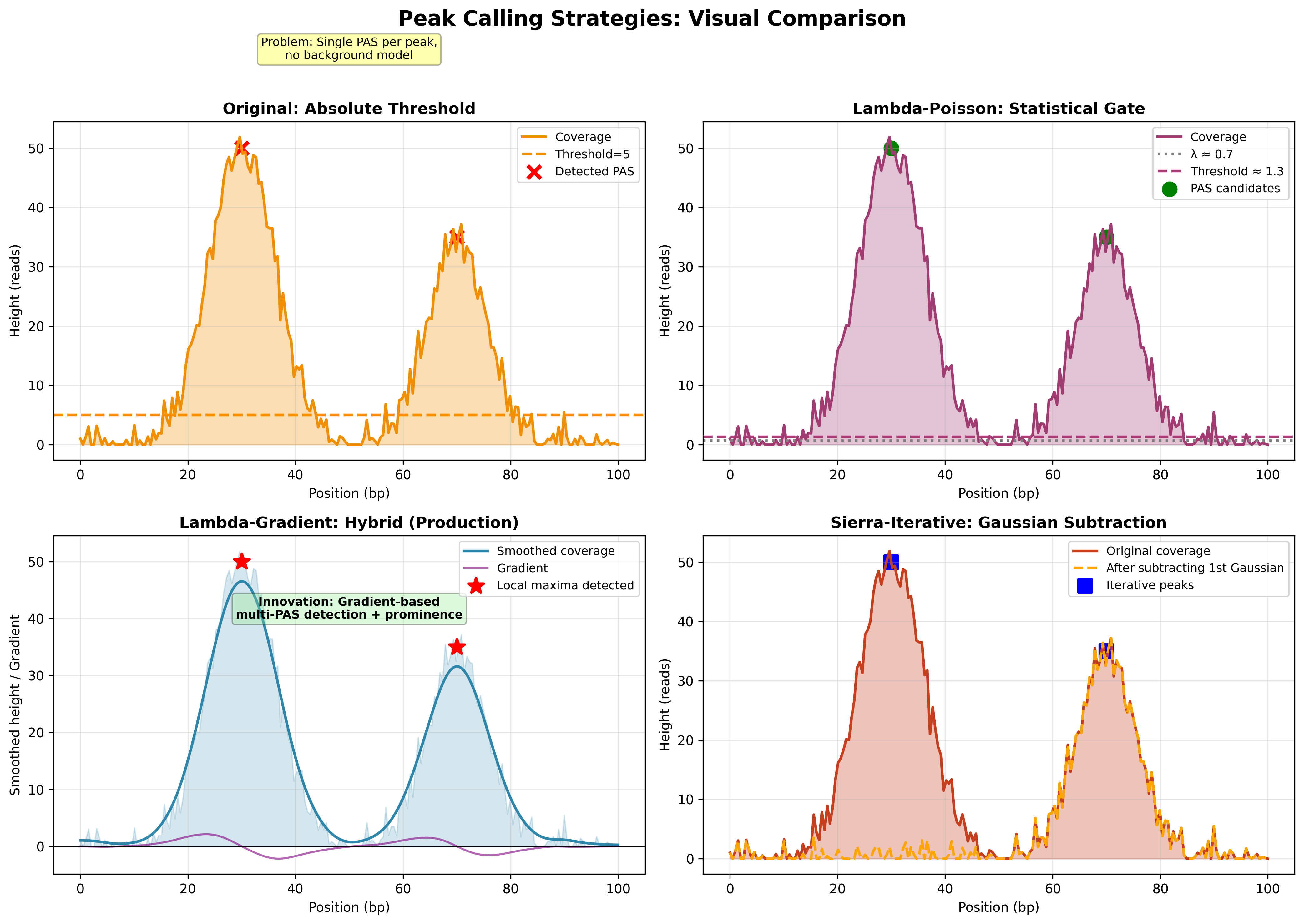 Strategy-level comparison across the benchmark set: number of detected PAS,
agreement with reference annotation, and runtime. Source: PeakATail Technical
Report (Mar 2026), Figure 2.
Strategy-level comparison across the benchmark set: number of detected PAS,
agreement with reference annotation, and runtime. Source: PeakATail Technical
Report (Mar 2026), Figure 2.
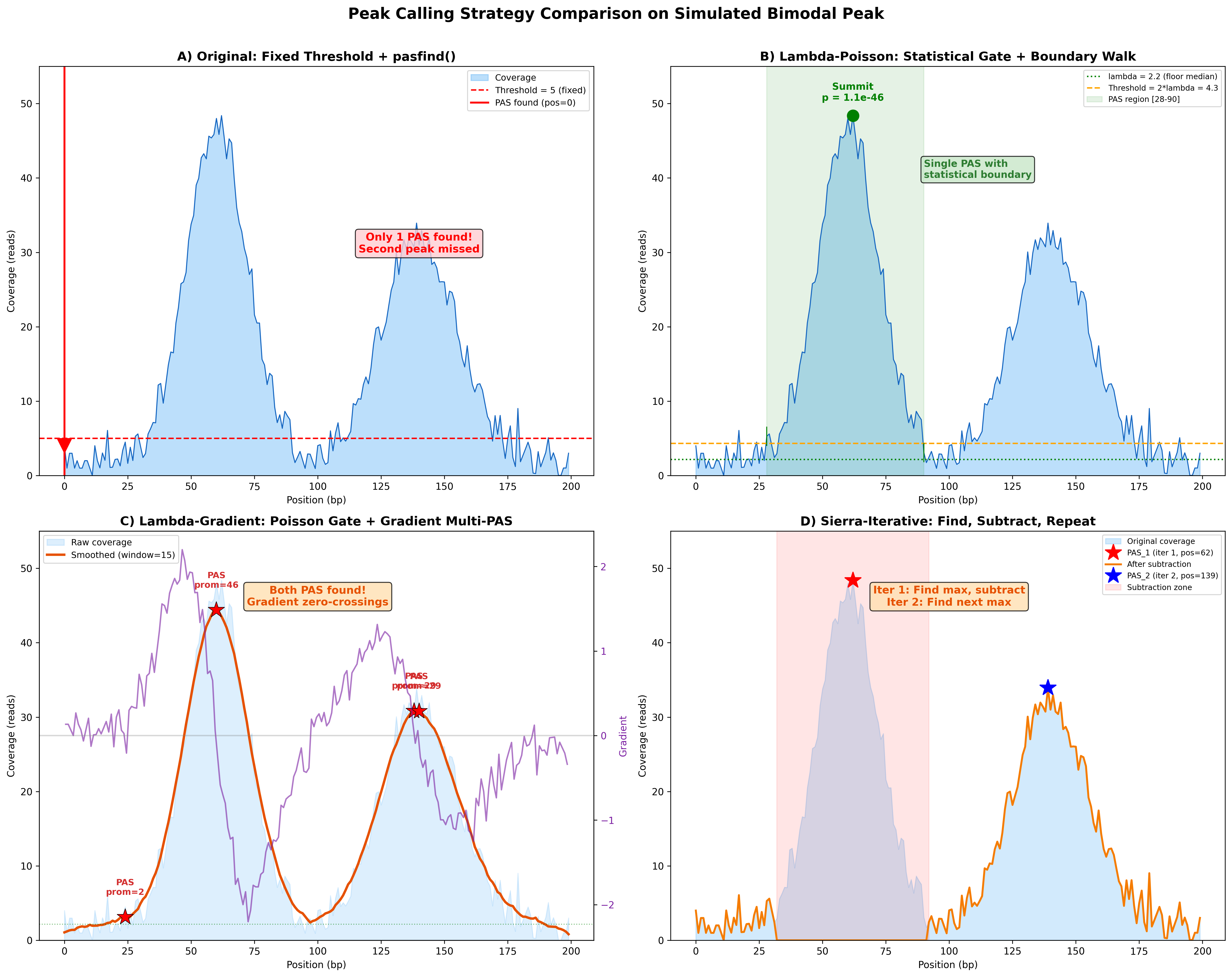 One-glance summary of each strategy's algorithmic idea — summit detection
(original / lambda_poisson) vs iterative subtraction (sierra_iterative) vs
gradient + significance (lambda_gradient).
One-glance summary of each strategy's algorithmic idea — summit detection
(original / lambda_poisson) vs iterative subtraction (sierra_iterative) vs
gradient + significance (lambda_gradient).
original¶
Registered name: original
Source: ema/strategies/original.py
Wraps the legacy Peak.pasfind() method unchanged. Produces IDENTICAL output
to the pre-refactor PeakATail code path. Exists so new strategies can be
evaluated against a frozen baseline.
Algorithm¶
- Call
peak.pasfind()on each peak region. - Return the (pas_1, pas_2) tuple — typically the single summit position.
Tunable hyperparameters¶
None. By design — this strategy exists to be deterministic.
When to use¶
A/B comparisons against new strategies. Reproducing old results from a previous PeakATail version exactly.
Limitations¶
Returns at most one PAS per peak region, even when a region clearly contains multiple distal sites. This was a recurring source of recall loss before the iterative strategies were added.
lambda_poisson¶
Registered name: lambda_poisson
Source: ema/strategies/lambda_poisson.py
MACS2-style: compute a local lambda from the region's background positions,
then test the summit's height against Poisson(lambda). Keep the summit as a
PAS only if the one-sided p-value beats alpha.
Algorithm¶
- Identify the summit position (max coverage) in the region.
- Compute
lambdafrom "floor" positions — positions with depth belowfloor_fraction × max_height. Thelambda_methodcontrols aggregation ("median","percentile20", or"global"). - Test
H₀: summit_depth ~ Poisson(lambda)one-sided. - Discard if
p ≥ alphaorsummit_depth < min_height.
Tunable hyperparameters¶
| Name | Default | Description |
|---|---|---|
lambda_method |
"median" |
Background aggregator — median is robust; percentile20 is more conservative |
min_height |
20 | Hard floor on summit depth before any p-value test |
alpha |
0.05 | Poisson p-value threshold |
floor_fraction |
0.1 | Positions below this fraction of max-height define the background |
When to use¶
Single-PAS regions where you want a statistical significance filter on noise peaks. Good baseline for benchmarking precision.
Limitations¶
Returns one PAS per region — multiple distal sites in the same UTR will
share a single called summit. Use sierra_iterative or lambda_gradient for
multi-PAS recovery.
sierra_iterative¶
Registered name: sierra_iterative
Source: ema/strategies/sierra_iterative.py
Based on Sierra (Patrick et al., Genome Biology 2020). Iteratively peels off the dominant peak from the coverage profile, then repeats — naturally surfaces multiple PAS per UTR.
Algorithm¶
- Find the position of maximum coverage; record as a PAS.
- Zero out a
±subtraction_windowneighbourhood around that position. - Repeat until either the remaining max falls below
min_heightAND belowmin_fraction × original_max, ormax_pasPAS have been called.
Tunable hyperparameters¶
| Name | Default | Description |
|---|---|---|
subtraction_window |
300 | bp zeroed-out on each side of every called summit |
min_height |
20 | Absolute minimum coverage for a position to be considered |
max_pas |
5 | Hard cap on PAS per region (safety) |
min_fraction |
0.1 | Stop when next peak's height < this × original max |
When to use¶
Whenever you want multiple PAS per UTR — the typical APA-discovery setup. The closest analog to the well-validated Sierra method.
Limitations¶
- No statistical significance test; iteration stops on raw-height thresholds
alone. Use
lambda_gradientif you want both multi-PAS recovery AND a per-summit p-value. - The subtraction_window is uniform regardless of underlying peak width — fine for typical 100–300 bp PAS clusters but may over-merge in longer-isoform regions.
lambda_gradient¶
Registered name: lambda_gradient
Source: ema/strategies/lambda_gradient.py
Hybrid: gradient-based candidate detection (smoothed coverage local maxima), then per-summit Poisson significance with locally estimated lambda.
Algorithm¶
- Smooth the coverage profile with a centered moving average of width
smooth_window. - Identify all positions where the first derivative crosses from positive to non-positive — these are candidate summits.
- For each candidate: estimate local
lambdafrom neighbouring floor positions and run a one-sided Poisson p-value test. - Apply
min_heightfloor andalphasignificance filter. - Merge candidates within
merge_window(so two summits 50 bp apart from noise oscillation collapse to one).
Tunable hyperparameters¶
| Name | Default | Description |
|---|---|---|
smooth_window |
typical 11 bp | Width of the moving-average smoother |
min_height |
20 | Absolute minimum summit depth |
alpha |
0.05 | Per-summit Poisson p-value threshold |
lambda_method |
"median" |
Background aggregator (same as lambda_poisson) |
merge_window |
typical 100 bp | Merge summits closer than this |
When to use¶
When you want multi-PAS detection and a statistical significance filter on each individual called PAS. The most expensive strategy per region (smoothing + per-summit test) but the most defensible for downstream differential testing.
Limitations¶
Smoothing trades sensitivity for noise robustness — narrow PAS (<10 bp) can be
suppressed by the moving average. If you see PAS recall drop on short
isoforms, reduce smooth_window.
Performance vs. the reference annotation¶
The PeakATail Technical Report (Mar 2026) benchmarks each strategy against the PolyASite 2.0 + polyA_DB v4 dual-database reference.
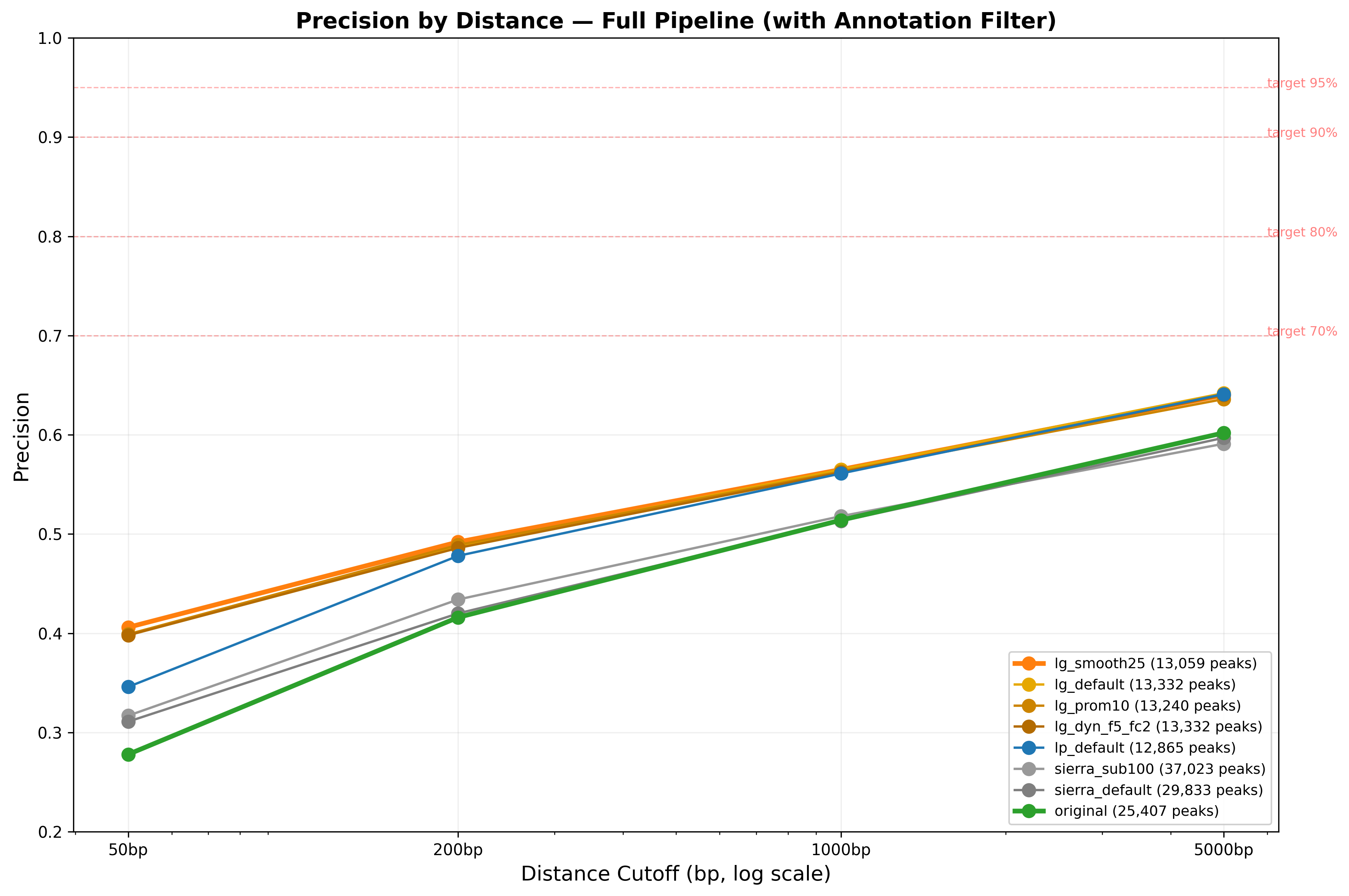 Precision (fraction of called PAS within 50 bp of a reference site) per
strategy. lambda_gradient achieves the highest precision; sierra_iterative
recovers the most multi-PAS hits.
Precision (fraction of called PAS within 50 bp of a reference site) per
strategy. lambda_gradient achieves the highest precision; sierra_iterative
recovers the most multi-PAS hits.
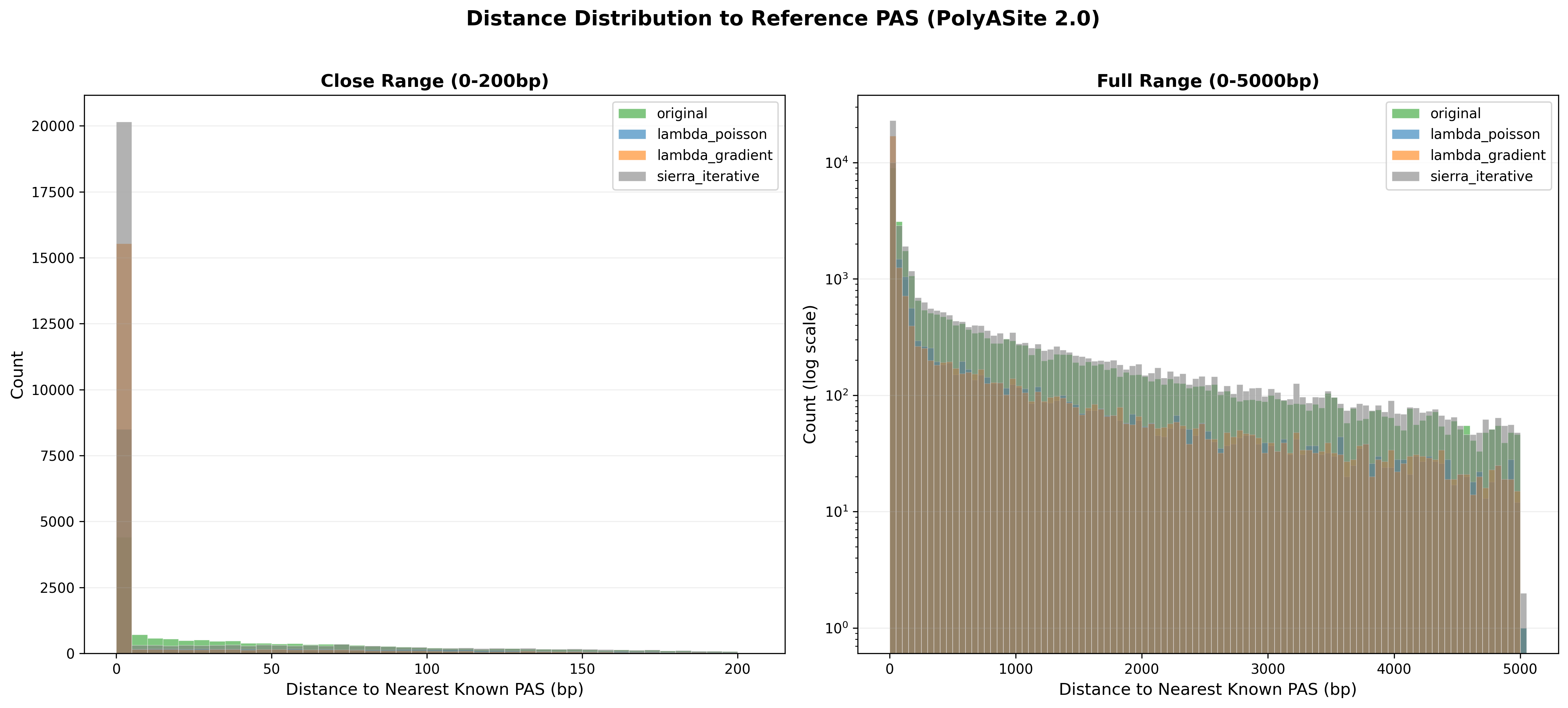 Per-strategy distribution of distances between called PAS and the nearest
reference site. A tight peak near 0 bp indicates accurate positioning.
Per-strategy distribution of distances between called PAS and the nearest
reference site. A tight peak near 0 bp indicates accurate positioning.
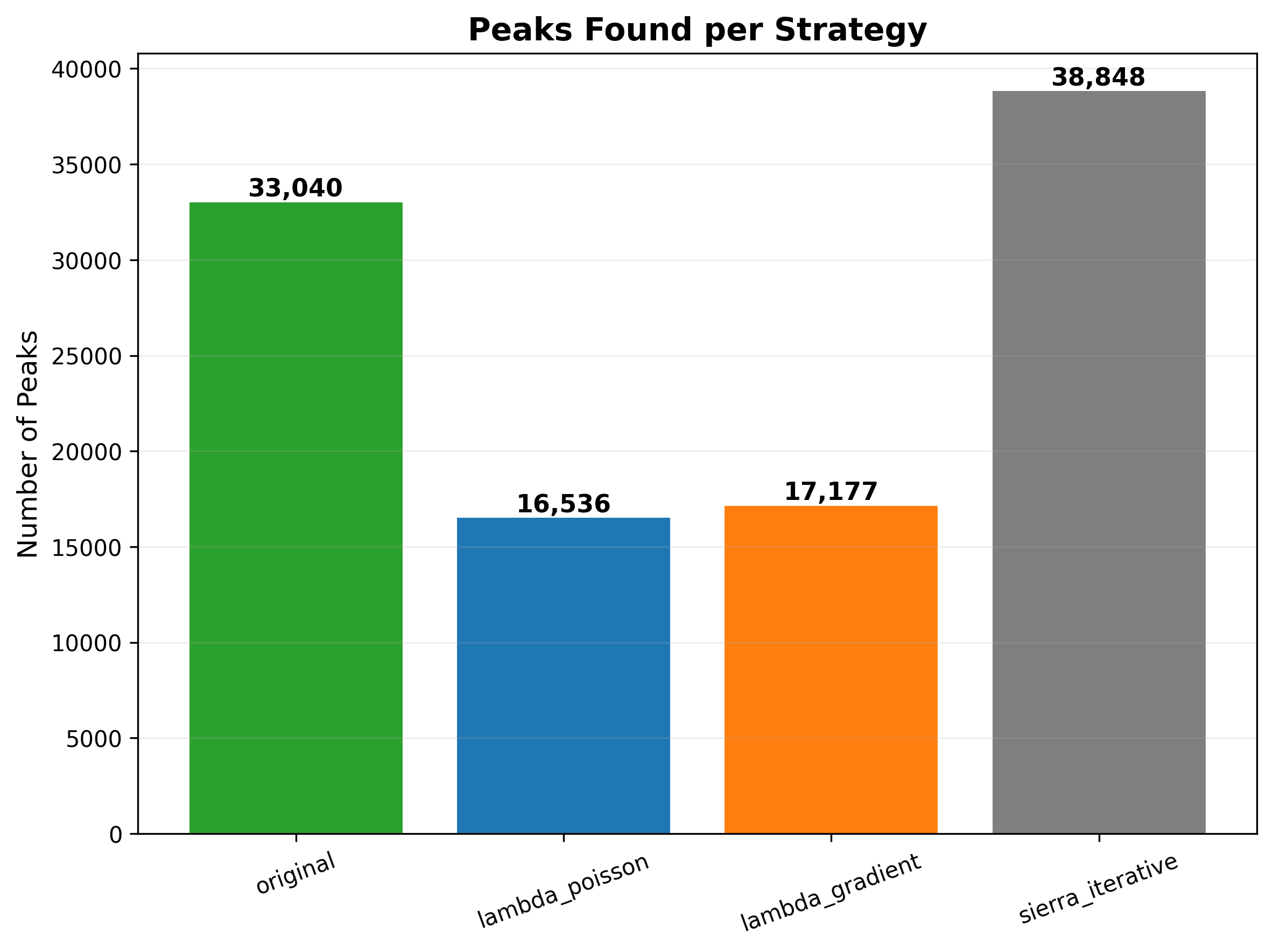 Total PAS called per strategy — the iterative / gradient strategies recover
substantially more multi-PAS UTRs.
Total PAS called per strategy — the iterative / gradient strategies recover
substantially more multi-PAS UTRs.
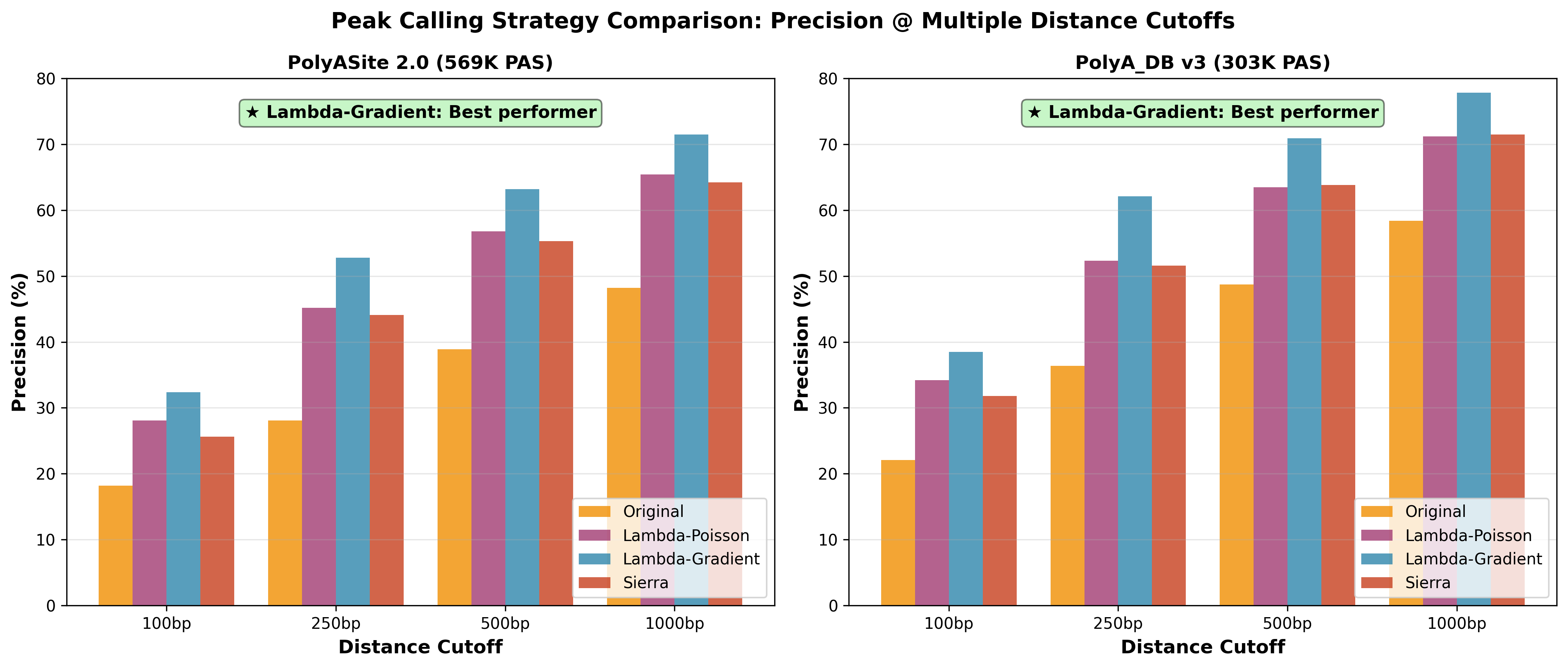 Precision–recall tradeoff across strategies and parameter sweeps.
Precision–recall tradeoff across strategies and parameter sweeps.
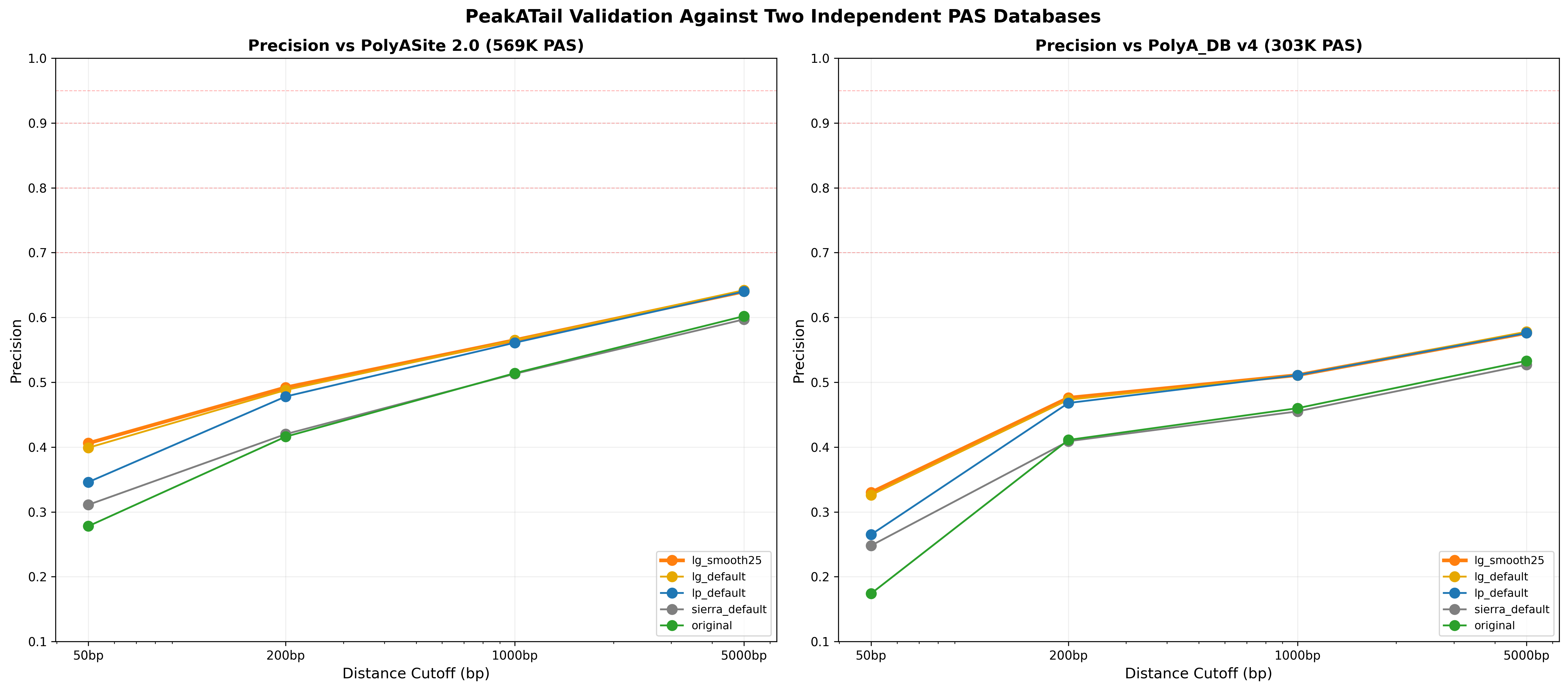 Validation against both PolyASite 2.0 and polyA_DB v4 — agreement metrics
across both databases independently.
Validation against both PolyASite 2.0 and polyA_DB v4 — agreement metrics
across both databases independently.
Choosing a strategy¶
A pragmatic decision tree:
Are you comparing against an existing PeakATail run from before
the strategy refactor?
└─ Yes → use `original` (exact reproducibility)
└─ No →
Do you want multiple PAS per UTR?
├─ No → use `lambda_poisson` (single-summit + significance)
└─ Yes →
Do you also want a significance test per summit?
├─ No → use `sierra_iterative` (fastest multi-PAS)
└─ Yes → use `lambda_gradient` (multi-PAS + p-value)
The default in the YAML schema is lambda_gradient, matching the
report's benchmark winner.
See also¶
ema run—--peak-strategyflag selects the strategy- PeakATail Technical Report — full benchmark methodology